
A Hypertext Transfer Protocol (HTTP) egy olyan kommunikációs protokoll, amelyet a webkiszolgálók (pl. egy weboldal) és az ügyfelek (pl. az Ön böngészője) közötti kommunikációra használnak az interneten.
A HTTP az ügyfél-kiszolgáló modell alapján működik: az ügyfél kérést küld a kiszolgálónak, és a kiszolgáló a kérés alapján egy adott választ küld vissza az ügyfélnek. Ez a kérés lehet bármi, egy weboldal lekérdezésétől kezdve egy felhasználói fiók létrehozásáig egy megadott felhasználónév és jelszó alapján. Az egyes kérések függetlenek egymástól: egyetlen kérésre egyetlen válasz érkezik vissza.
A HTTP mellett gyakran találkozunk a webcímekben a HTTPS protokollal is. Ez a Hypertext Transfer Protocol Secure rövidítése, és azt jelzi, hogy a kommunikáció egy extra biztonsági réteggel van ellátva, így a rosszindulatú szereplők nem tudják könnyen megszakítani azt. Az SSL-ről szóló korábbi bejegyzésünkben elmagyaráztuk, hogy ez pontosan mit jelent és hogyan működik. Fontos megjegyezni, hogy mindaz, amit ebben a cikkben tárgyalunk, a HTTPS-re is vonatkozik.
A HTTP-kérelmek számos különböző célra használhatók, amelyek mindegyikét saját, úgynevezett “módszerrel” jelölik. E módszerek közül csak néhány kiválasztott módszert használnak gyakran, és ezek ismerete fontos. A legelterjedtebb módszer az, amellyel Ön is eljutott erre a blogra: a GET-módszer. Ez a módszer, ahogy a neve is mutatja, a kiszolgálóról való információ lekérdezésre szolgál. Az egyiket a böngészője küldte, amikor rákattintott egy linkre, hogy elolvassa ezt a cikket, hogy lekérje ennek a weboldalnak a HTML-jét.
Ha például egy fiókba való bejelentkezéshez vagy egy űrlap kitöltéséhez szeretne információt küldeni egy webkiszolgálónak, akkor a POST módszert használja. Két másik gyakran használt módszer a PUT és a DELETE. A PUT nagyon hasonlít a POST-hoz, de nem új rekordok létrehozására, hanem meglévő rekordok frissítésére szolgál, a DELETE pedig, ahogy azt már kitalálhattad, bizonyos adatok törlésének kérésére szolgál.
De hogyan is használják pontosan ezeket a módszereket egy kérés elküldésekor?

A fenti ábra egy HTTP-kérés vizuális ábrázolását mutatja be. Ez elsőre ijesztőnek tűnhet, de lebontjuk, és megnézzük az egyes részeket. Ez egy kérés egy kiszolgálóhoz, amely feldolgozza az általunk megadott szöveget, és ebben az esetben egy HTML-oldalt ad vissza nekünk a szövegünkkel egy címsorban. A kérés első része, amelyet ennek a szervernek küldünk, a kérés sora, amely három összetevőből áll: a módszerből, a célból és a protokollváltozatból. Ez a sor közli a szerverrel, hogy milyen műveletet szeretnénk végrehajtani, melyik célpontban kell végrehajtani ezt a műveletet, és - a félreértések elkerülése végett - milyen pontos protokollt szeretnénk használni a kommunikációhoz. Esetünkben ez egy GET-kérés, mivel egy HTML-oldalt szeretnénk lekérni. Ezt a kérést a (fiktív) /test végpontra küldjük a HTTP 1.1-es verziójú protokollt használva.
Következnek a fejlécek. A kérés fejléceit metaadatoknak tekinthetjük, amelyek tájékoztatják a szervert a kért adatokról és a kérést küldő kliensről. Ezek a fejlécek tovább oszthatók kategóriákra, de most ezeket figyelmen kívül hagyjuk. A kérésünkben több fejlécet kell átadnunk, hogy megmondjuk a szervernek, hogy milyen a kérésünk - a Content fejléceken keresztül - és mit várunk vissza a válaszból - az Accept fejléceken keresztül. A host fejléc biztosítja, hogy a kérés a megfelelő szerverre kerüljön.
A User-Agent fejléc közli a szerverrel, hogy milyen eszközön vagyunk, és milyen böngészőt használunk. Ez a fejléc minden eszköztípusnál másképp néz ki, de általában Mozilla/5.0-val kezdődik, hogy jelezze, hogy a böngésző kompatibilis a Mozillával. Ez csak egy kis válogatása a lehetséges fejléceknek, amelyeket egy kéréssel együtt átadhatunk. A teljes áttekintésért tekintse meg a Mozilla dokumentációját a HTTP fejlécekről.
Végül, a fejlécektől egyetlen üres sorral elválasztva, a kérés teste következik. Ez opcionális, mivel nem minden kérésnél kell tartalmat küldeni a szervernek, de a mi esetünkben néhány szöveget szeretnénk elküldeni, amely egy címsor formájában jelenik meg. Ez egy nagyon egyszerű példa, a kérés teste ennél sokkal összetettebb is lehet, akár több erőforrással.
A kérés feldolgozása után a szerver egy választ küld vissza. Ha a kérés sikeres, a válasz így nézhet ki:
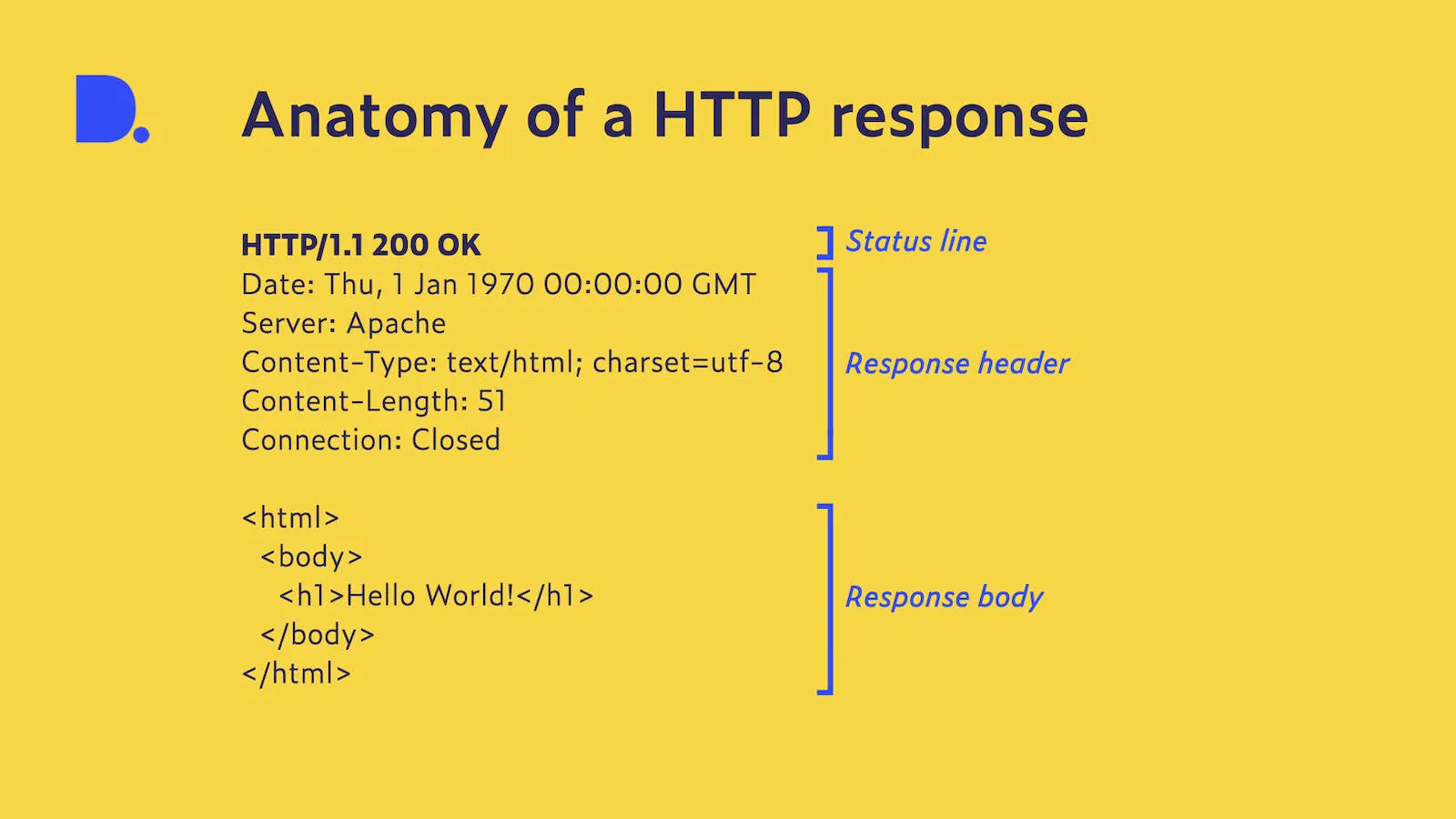
A HTTP-válasz felépítése nagyon hasonló a kéréshez. Egy státuszsorral kezdődik, amely egy státuszkód és egy kiegészítő státuszüzenet segítségével tájékoztatja az ügyfelet arról, hogy melyik HTTP-verziót használják, és hogy a kérést hogyan kezelték. Ezek az állapotkódok öt kategóriába sorolhatók, és a kérés sikerét vagy sikertelenségét jelzik. Mivel a kérésünk sikeres volt, a 200-as státuszkódot kaptuk az “OK” szöveggel, ami azt jelzi, hogy minden a terv szerint zajlott. Ez és más státuszkódok megtalálhatók a saját adatainkban, amelyekben minden általunk feltérképezett weboldal válaszkódját és fejlécét elmentjük.
Az állapotsort a válasz fejlécek követik, amelyek a szerverről és a visszaküldött tartalomról adnak információt. Ez a tartalom ismét egy üres sorral van elválasztva a fejlécektől, és esetünkben egy weboldal HTML-struktúráját tartalmazza, a szervernek küldött szöveggel együtt, egy címsorban.
Remélhetőleg most már egy kicsit többet tudsz az internet összetett természetéről és arról, hogy mi zajlik a színfalak mögött, amikor meglátogatod a kedvenc receptes blogod vagy frissíted a LinkedIn-profilodat.
2023-02-21